多方安全计算平台PrivPy
PrivPy 多方安全计算平台实现了支持通用计算类型、高性能、集群化和可扩展的解决方案。 支持标准的 Python 语言和 SQL 操作,兼容 NumPy 和 Pytorch 等函数库,能够支持包括绝大多数机器学习算法在内的计算类型和系统实现,极大的降低了用户使用密文计算的学习曲线,实现了多方安全计算产品的实际可用性和商业易用性。 同时,PrivPy 自主灵活的模块化组合模式和多种部署方式能够满足广泛用户群体在使用和部署中的多样化需求。
缓存模块
- 支持持久化缓存
- 密文缓存分域管理
- HDD + SDD
- 数据加密上传
- 提升密文计算性能
研发辅助模块
- 支持 JupyterNotebook
- 图表分析
- 版本管理
- 多用户管理
- 数据集检索
协同计算模块
- 支持明文密文协同计算模式
- 计算任务预处理及后处理
- 预处理结果形态自动判断
AI 计算模块
- 支持常用机器学习算法的训练和预测
- AI 计算模块全面的库函数
- 丰富的机器学习算法
- 算法性能大幅度优化
存证模块
- 存证过程透明可信
- 存证结果安全存储,不被篡改
- 多维度存证为密文计算各方解决争议
SQL 模块
- 支持标准 SQL 语法
- 分布式并行执行
- 离线处理
- 结果缓存
- 恶意 SQL 检测
产品介绍Overview
PrivPy 标准平台是华控清交多方安全计算产品系列的核心和基础,能够满足广泛用户群体保护多方数据隐私且实现协同计算的基本需求。 在此基础上,用户可以结合实际场景以及自身实际需求,通过增加相关模块(包括存证模块、研发辅助模块、AI计算模块、缓存模块、SQL模块、协同计算模块6大功能模块) 对标准平台进行补充以实现更多功能。
产品特色Features
灵活部署
支持实体部署、容器化部署以及云上部署等多种灵活的部署方式。
模块化组合
采用灵活的1+N自助式模块组合模式,用户可以基于 PrivPy 标准平台,根据实际场景选择相应功能模块以满足定制化需求。
通用计算
支持各种类型的算法,包括人工智能领域大多数的机器学习算法和多种数据类型。
性能优异
采用分布式密文计算架构,同时支持横向扩展,实现密文计算的高并发、高性能、高可用
易用性强
采用通用的Python和SQL进行操作,兼容NumPy和Pytorch等函数库,极大的降低了用户密文计算的学习曲线。
应用场景Scenarios
- 政府监管
- 数据交易
- 联合挖掘
- 数据增值
- AI 安全预测
- 联合模型训练
应用大数据推动政府监管是政府治理能力现代化的重要途径。在政府监管的场景下,出于数据隐私安全和自身利益的考虑,被监管方不会轻易地分享这些数据,监管方存储海量数据也存在着巨大的数据泄露风险。通过多方安全计算技术能够在不暴露数据明文的前提下,以数据密文形态进行统计和分析,既保证了被监管方的数据使用安全,又降低了监管方存储的海量数据泄露的风险。
技术原理principle
同态承诺
同态承诺是一种允许一个人向其他人提交任何选定数值而又不泄露该值的密码协议,承诺提交后不能更改,且事后可公开验证。同态承诺允许在提交的承诺上进行计算而不失去承诺的保密、不可更改及事后可验证的特征。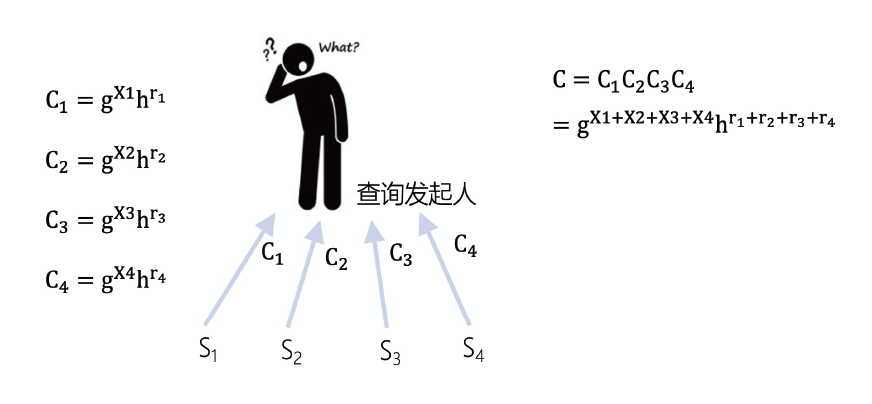
同态加密
同态加密即为各参与者将自己的输入加密后一起发给某计算服务器,服务器直接在密文上进行计算,计算后将得到的结果的密文发送给指定结果方,结果方再将结果的密文解密,即可得到最终的计算结果。如此一来,计算服务器一直在密文上操作,无法看到任何有效信息,而参与者也只拿到最后的结果,看不到中间结果。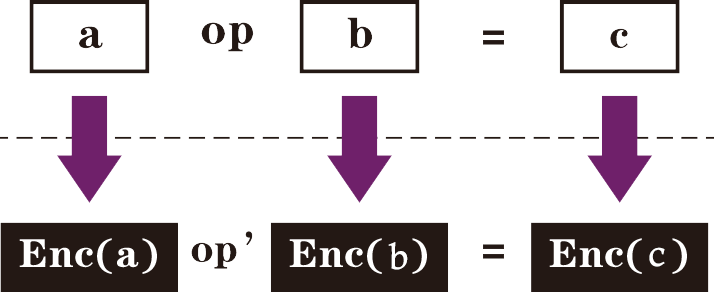
秘密分享
秘密分享的基本思想是将数据切割成多份,并分发给不同的参与者,每个参与者持有其中一份,协作完成计算任务(比如加法、乘法运算)。因为参与者看不到数据全量信息,从而实现数据隐私保护。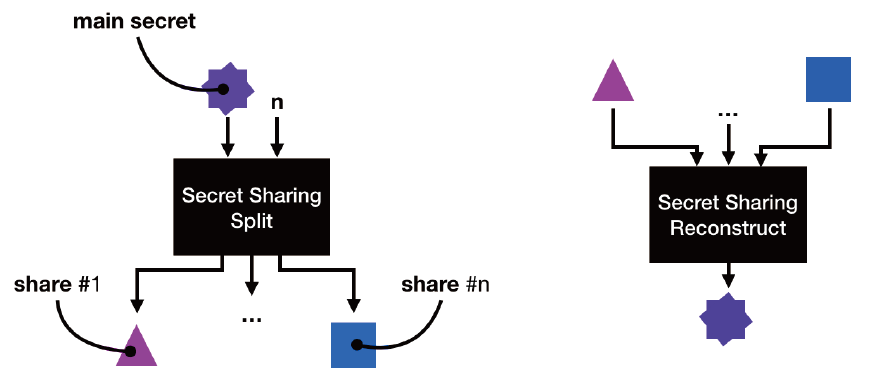
混淆电路
混淆电路的基本思想是将计算电路的每个门都加密并打乱,保证计算过程中不会泄露原始输入和中间结果。双方根据各自输入依次进行计算、解密方可得到唯一的正确结果,无法得到结果以外的其他信息,从而实现双方安全计算。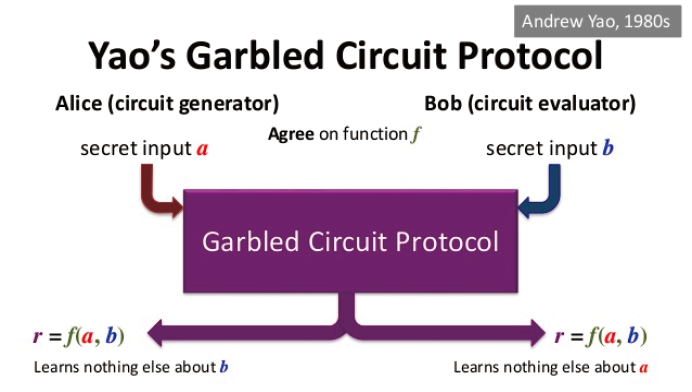
不经意传送
不经意传输是一种可保护隐私的双方通信协议,能使通信双方以一种选择模糊化的方式传送消息。不经意传输协议是密码学的一个基本协议,它使得服务的接收方以不经意的方式得到服务发送方输入的某些消息,这样就可以保护接受者的隐私不被发送者所知道。
S每次发送2个信息m0和m1 ,而R每次输入一个选择b。当协议结束的时候,S无法获得关于b 的任何有价值的信息,而R只能获得mb ,对于m1−b ,R也一无所知。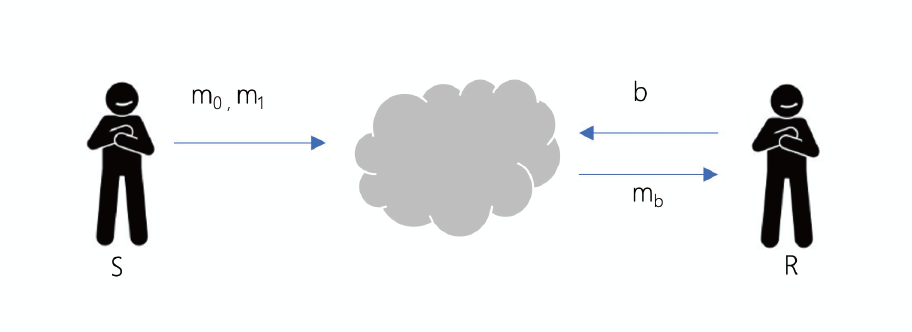
零知识证明
零知识证明是由S.Goldwasser、S.Micali及C.Rackoff在20世纪80年代初提出的。它指的是证明者能够在不向验证者提供任何有用的信息的情况下,使验证者相信某个论断是正确的。
零知识证明实质上是一种涉及两方或更多方的协议,即两方或更多方完成一项任务所需采取的一系列步骤。证明者向验证者证明并使其相信自己知道或拥有某一消息,但证明过程不能向验证者泄漏任何关于被证明消息的信息。